本文共 24021 字,大约阅读时间需要 80 分钟。
微服务的消费模式
基于http的客户端经常被用作微服务的消费者,因为http本身是平台无关的、语言无关的,所以基于http的客户端往往会被广大的社区支持
服务直连模式
特点:
- 简洁明了,只要传入一个
URL,就能直接连过去,获取到资源 - 平台语言无关性,非常直白,不需要特定框架、技术,能实现平台无关、语言无关
- 无法保证服务的可用性,当需要链接某个
IP下的某个资源时,如果这个IP地址或这个IP地址所绑定的主机宕机了,这个资源就无法拿到,因为服务直连模式无法做到负载均衡,也就无法保证服务的可用性 - 生产环境比较少用
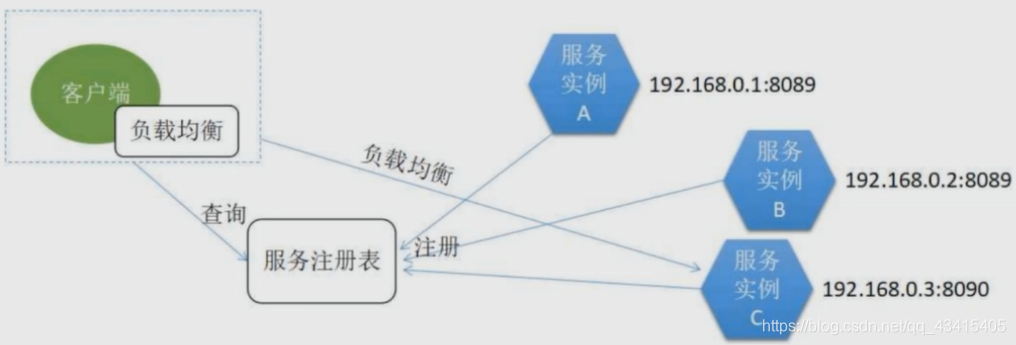
客户端发现模式
- 服务实例启动后,将自己的位置信息提交到服务注册表
- 客户端从服务注册表进行查询,来获取可用的服务实例
- 客户端自行使用负载均衡算法从多个服务实例中选择出一个
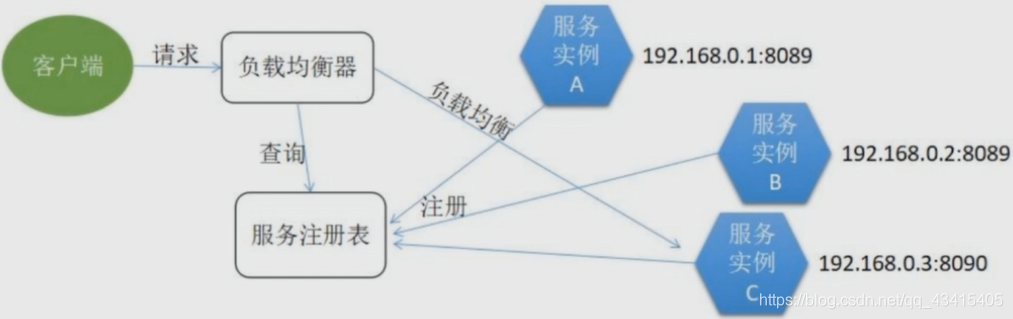
服务端发现模式
与客户端发现模式最大的区别在于:负载均衡不是由客户端来做,而是在服务端实现,负载均衡器是独立部署在服务端的
常见微服务的消费者
Apache HttpClient
用来提供高效、功能丰富的http协议的客户端工具包,能支持http协议最新的版本和建议。Apache HttpClient能对JDK提供一些非常好的补充,方便开发人员测试基于http的接口,从而提高开发效率及代码健壮性
Apache HttpClient的用法
添加依赖
//依赖关系dependencies { //添加Apache HttpClient依赖 compile('org.apache.httpcomponents:httpclient:4.5.6')} 注入restTemplate
import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.web.client.RestTemplateBuilder;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.web.client.RestTemplate;@Configuration//rest配置类,配置restTemplatepublic class RestConfiguration { @Autowired private RestTemplateBuilder builder; @Bean public RestTemplate restTemplate() { return builder.build(); } } 使用
@Servicepublic class WeatherDataServiceImpl implements WeatherDataService { @Autowired private RestTemplate restTemplate; private WeatherResponse doGetWeather(String uri) { ResponseEntity respString = restTemplate.getForEntity(uri, String.class); //... } //...} Ribbon
Ribbon是Spring Cloud中的一个组件,是基于Netflix Ribbon实现客户端负载均衡的一个工具,基于HTTP和TCP来实现客户端的负载均衡
Spring Cloud Ribbon虽然只是一个工具类框架,它不像服务注册中心、配置中心、API网关那样需要独立部署,但是它几乎存在于每一个Spring Cloud构建的微服务和基础设施中。因为微服务间的调用,API网关的请求转发等内容,实际上都是通过Ribbon来实现的,包括后续我们的Feign,也是基于Ribbon实现的工具。所以,对Spring Cloud Ribbon的理解和使用,对于我们使用Spring Cloud来构建微服务非常重要。
负载均衡在系统架构中是一个非常重要,并且是不得不去实施的内容。因为负载均衡是对系统的高可用、网络压力的缓解和处理能力扩容的重要手段之一。
我们通常说的负载均衡都指的是服务端负载均衡,其中分为硬件负载均衡和软件负载均衡。硬件负载均衡主要通过在服务器节点之间安装专门用于负载均衡的设备,比如F5等;而软件负载均衡则是通过在服务器上安装一些具有均衡负载功能或模块的软件来完成请求分发工作,比如Nginx等。不论采用硬件负载均衡还是软件负载均衡,只要是服务端负载均衡都能以类似下图的架构方式构建起来:
 硬件负载均衡的设备或是软件负载均衡的软件模块都会维护一个下挂可用的服务端清单,通过心跳检测来剔除故障的服务端节点以保证清单中都是可以正常访问的服务端节点。当客户端发送请求到负载均衡设备的时候,该设备按某种算法(比如线性轮询、按权重负载、按流量负载等)从维护的可用服务端清单中取出一台服务端的地址,然后进行转发。
硬件负载均衡的设备或是软件负载均衡的软件模块都会维护一个下挂可用的服务端清单,通过心跳检测来剔除故障的服务端节点以保证清单中都是可以正常访问的服务端节点。当客户端发送请求到负载均衡设备的时候,该设备按某种算法(比如线性轮询、按权重负载、按流量负载等)从维护的可用服务端清单中取出一台服务端的地址,然后进行转发。 而客户端负载均衡和服务端负载均衡最大的不同点在于上面所提到的服务清单所存储的位置。在客户端负载均衡中,所有客户端节点都维护着自己要访问的服务端清单,而这些服务端的清单来自于服务注册中心。同服务端负载均衡的架构类似,在客户端负载均衡中也需要心跳去维护服务端清单的健康性,只是这个步骤需要与服务注册中心配合完成。在Spring Cloud实现的服务治理框架中,默认会创建针对各个服务治理框架的Ribbon自动化整合配置,比如Eureka中的org.springframework.cloud.netflix.ribbon.eureka.RibbonEurekaAutoConfiguration,Consul中的org.springframework.cloud.consul.discovery.RibbonConsulAutoConfiguration。在实际使用的时候,我们可以通过查看这两个类的实现,以找到它们的配置详情来帮助我们更好地使用它。
通过Spring Cloud Ribbon的封装,我们在微服务架构中使用客户端负载均衡调用非常简单,只需要如下两步:
- 服务提供者只需要启动多个服务实例并注册到一个注册中心或是多个相关联的服务注册中心。
- 服务消费者直接通过调用被
@LoadBalanced注解修饰过的RestTemplate来实现面向服务的接口调用。
这样,我们就可以将服务提供者的高可用以及服务消费者的负载均衡调用一起实现了。
Ribbon的每个负载均衡器一起协作,可以根据需要与远程服务器进行交互,来获取包含命名客户端名词的集合,Ribbon经常与Eureka结合使用,在典型的分布式部署中,Eureka为所有的微服务实例提供服务注册,Ribbon提供服务消费的客户端
Ribbon有很多负载均衡的算法
Ribbon的用法
添加依赖
//依赖关系dependencies { //添加Spring Cloud Starter Netflix Ribbon依赖 compile('org.springframework.cloud:spring-cloud-starter-netflix-ribbon')} build.gradle完整代码如下:
//buildscript代码块中脚本优先执行buildscript { //ext用于定义动态属性 ext { springBootVersion = '2.0.0.M3' } //使用了Maven的中央仓库及Spring自己的仓库(也可以指定其他仓库) repositories { //mavenCentral() maven{ url "https://repo.spring.io/snapshot" } maven{ url "https://repo.spring.io/milestone" } maven{ url "http://maven.aliyun.com/nexus/content/groups/public/" } } //依赖关系 dependencies { //classpath声明了在执行其余的脚本时,ClassLoader可以使用这些依赖项 classpath("org.springframework.boot:spring-boot-gradle-plugin:${springBootVersion}") }}//使用插件apply plugin: 'java'apply plugin: 'eclipse'apply plugin: 'org.springframework.boot'apply plugin: 'io.spring.dependency-management'//指定了生成的编译文件的版本,默认是打成了jar包group = 'com.study.spring.cloud'version = '1.0.0'//指定编译.java文件的JDK版本sourceCompatibility = 1.8//使用了Maven的中央仓库及Spring自己的仓库(也可以指定其他仓库)repositories { //mavenCentral() maven{ url "https://repo.spring.io/snapshot" } maven{ url "https://repo.spring.io/milestone" } maven{ url "http://maven.aliyun.com/nexus/content/groups/public/" }}ext { springCloudVersion = 'Finchley.M2'}//依赖关系dependencies { //该依赖用于编译阶段 compile('org.springframework.boot:spring-boot-starter-web') //Eureka Client compile('org.springframework.cloud:spring-cloud-starter-netflix-eureka-client') //添加Spring Cloud Starter Netflix Ribbon依赖 compile('org.springframework.cloud:spring-cloud-starter-netflix-ribbon') //该依赖用于测试阶段 testCompile('org.springframework.boot:spring-boot-starter-test')}//Spring Cloud依赖管理dependencyManagement{ imports{ mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}" }} 注入
为RestTemplate增加@LoadBalanced注解:
import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.web.client.RestTemplateBuilder;import org.springframework.cloud.client.loadbalancer.LoadBalanced;import org.springframework.cloud.netflix.ribbon.RibbonClient;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.web.client.RestTemplate;@Configuration@RibbonClient(name = "ribbon-client",configuration = RibbonConfiguration.class)public class RestConfiguration { @Autowired private RestTemplateBuilder builder; @Bean @LoadBalanced public RestTemplate restTemplate() { return builder.build(); } } 配置
import com.netflix.loadbalancer.IPing;import com.netflix.loadbalancer.PingUrl;import org.springframework.cloud.netflix.ribbon.ZonePreferenceServerListFilter;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configurationpublic class RibbonConfiguration { @Bean public ZonePreferenceServerListFilter serverListFilter(){ ZonePreferenceServerListFilter filter = new ZonePreferenceServerListFilter(); filter.setZone("myZone"); return filter; } @Bean public IPing ribbonPing(){ return new PingUrl(); }} 使用
直接通过RestTemplate发起请求:
import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RestController;import org.springframework.web.client.RestTemplate;@RestControllerpublic class CityController { @Autowired private RestTemplate restTemplate; @GetMapping("/cities") public String listCity(){ //通过应用名词来查找 String body=restTemplate.getForEntity("http://msa-weather-city-eureka/cities", String.class).getBody(); return body; }} 这里请求的host位置并没有使用一个具体的IP地址和端口的形式,而是采用了服务名的方式组成。那么这样的请求为什么可以调用成功呢?因为Spring Cloud Ribbon有一个拦截器,它能够在这里进行实际调用的时候,自动的去选取服务实例,并将实际要请求的IP地址和端口替换这里的服务名,从而完成服务接口的调用。
应用配置application.properties
#应用名称spring.application.name=micro-weather-eureka-client-ribbon#指定Eureka服务器地址eureka.client.service-url.defaultZone=http://localhost:8761/eureka/
RestTemplate
RestTemplate针对几种不同请求类型和参数类型的服务调用实现:
GET请求
在RestTemplate中,对GET请求可以通过如下两个方法进行调用实现:
getForEntity函数getForObject函数
getForEntity函数
getForEntity方法返回的是ResponseEntity,该对象是Spring对HTTP请求响应的封装,其中主要存储了HTTP的几个重要元素,比如HTTP请求状态码的枚举对象HttpStatus(也就是我们常说的404、500这些错误码)、在它的父类HttpEntity中还存储着HTTP请求的头信息对象HttpHeaders以及泛型类型的请求体对象。比如下面的例子,就是访问USER-SERVICE服务的/user请求,同时最后一个参数didi会替换url中的{1}占位符,而返回的ResponseEntity对象中的body内容类型会根据第二个参数转换为String类型。
RestTemplate restTemplate=new RestTemplate();ResponseEntityresponseEntity=restTemplate.getForEntity("http://USER-SERVICE/user?name={1}",String.class,"didi" );String body=responseEntity.getBody();
若我们希望返回的body是一个User对象类型,也可以这样实现:
RestTemplate restTemplate=new RestTemplate();ResponseEntityresponseEntity=restTemplate.getForEntity("http://USER-SERVICE/user?name={1}",User.class,"didi" );User body=responseEntity.getBody();
上面的例子是比较常用的方法,getForEntity函数实际上提供了以下三种不同的重载实现:
//url为请求的地址,responseType为请求响应体body的包装类型,urlVariables为url中的参数绑定//由于urlVariables参数是一个数组,所以它的顺序会对应url中占位符定义的数字顺序getForEntity(String url,Class responseType,Object... urlVariables);//只有urlVariables的参数类型与上面的方法不同//这里使用了Map类型,所以使用该方法进行参数绑定时需要在占位符中指定Map中参数的key值getForEntity(String url,Class responseType,Map urlVariables);//使用URI对象来替代之前的url和urlVariables参数来指定访问地址和参数绑定//URI是JDK java.net包下的一个类,它表示一个统一资源标识符(Uniform Resource Identifier)引用getForEntity(URI url,Class responseType);
getForObject函数
getForObject方法可以理解为对getForEntity的进一步封装,它通过HttpMessageConverterExtractor对Http的请求响应体body内容进行对象转换,实现请求返回包装好的对象内容。比如:
RestTemplate restTemplate=new RestTemplate();String result=restTemplate.getForObject(uri, String.class);
当body是一个User对象时,可以直接这样实现:
RestTemplate restTemplate=new RestTemplate();User result=restTemplate.getForObject(uri, User.class);
当不需要关注请求响应除body外的其他内容时,该函数就非常好用,可以少一个从Response中获取body的步骤。它与getForEntity函数类似,也提供了三种不同的重载实现:
//url参数指定访问的地址,responseType定义该方法的返回类型,urlVariables为url中占位符对应的参数getForObject(String url, Class responseType, Object... urlVariables);//使用Map类型的urlVariables替代上面数组形式的urlVariables//使用时在url中需要将占位符的名称与Map类型中的key一一对应设置getForObject(String url, Class responseType, Map urlVariables);//使用URI对象来替代之前的url和urlVariables参数使用getForObject(URI url, Class responseType);
POST请求
在RestTemplate中,对POST请求时可以通过如下三个方法进行调用实现:
postForEntity函数postForObject函数postForLocation函数
postForEntity函数
postForEntity函数方法会在调用后返回ResponseEntity<T>对象,其中T为请求响应的body类型。比如下面这个例子,使用postForEntity提交POST请求到USER-SERVICE服务的/user接口,提交的body内容为user对象,请求响应返回的body类型为String。
RestTemplate restTemplate=new RestTemplate();User user=new User("didi",30);ResponseEntity responseEntity=restTemplate.postForEntity("http://USER-SERVICE/user", user, String.class);String body=responseEntity.getBody(); postForEntity函数也实现了三种不同的重载方法:
postForEntity(String url, Object request, Class responseType, Object ... urlVariables);postForEntity(String url, Object request, Class responseType, Map urlVariables);postForEntity(URI url, Object request, Class responseType);
上面新增加的request参数可以是一个普通对象,也可以是一个HttpEntity对象。如果是一个普通对象,而非HttpEntity对象的时候,RestTemplate会将请求对象转换为一个HttpEntity对象来处理,其中Object就是request的类型,request内容会被视作完整的body来处理;而如果request是一个HttpEntity对象,那么就会被当作一个完成的HTTP请求对象来处理,这个request中不仅包含了body的内容,也包含了header的内容。
postForObject函数
postForObject方法作用是简化postForEntity的后续处理。通过直接将请求响应的body内容包装成对象来返回使用,比如下面的例子:
RestTemplate restTemplate=new RestTemplate();User user=new User("didi",30);String postResult=restTemplate.postForObject("http://USER-SERVICE/user", user, String.class); postForObject函数也实现了三种不同的重载方法:
postForObject(String url, Object request, Class responseType, Object ... urlVariables);postForObject(String url, Object request, Class responseType, Map urlVariables);postForObject(URI url, Object request, Class responseType);
postForLocation函数
postForLocation方法实现了以POST请求提交资源,并返回新资源的URI,比如下面的例子:
RestTemplate restTemplate=new RestTemplate();User user=new User("didi",30);URI responseURI=restTemplate.postForLocation("http://USER-SERVICE/user", user); postForLocation函数也实现了三种不同的重载方法:
postForLocation(String url, Object request, Object ... urlVariables);postForLocation(String url, Object request, Map urlVariables);postForLocation(URI url, Object request);
由于postForLocation函数会返回新资源的URI,该URI就相当于指定了返回类型,所以此方法实现的POST请求不需要像postForEntity和postForObject那样指定responseType。
PUT请求
在RestTemplate中,对PUT请求可以通过put方法进行调用实现,比如:
RestTemplate restTemplate=new RestTemplate();Long id=10001L;User user=new User("didi",30);restTemplate.put("http://USER-SERVICE/user/{1}",user,id); put函数也实现了三种不同的重载方法:
put(String url, Object request, Object ... urlVariables);put(String url, Object request, Map urlVariables);put(URI url, Object request);
put函数为void类型,所以没有返回内容,也就没有其他函数定义的responseType参数,除此之外的其他传入参数定义为用法与postForObject基本一致。
DELETE请求
在RestTemplate中,对DELETE请求可以通过delete方法进行调用实现,比如:
RestTemplate restTemplate=new RestTemplate();Long id=10001L;restTemplate.delete("http://USER-SERVICE/user/{1}",id); delete函数也实现了三种不同的重载方法:
delete(String url, Object ... urlVariables);delete(String url, Map urlVariables);delete(URI url);
由于我们在进行REST请求时,通常都将DELETE请求的唯一标识拼接在url中,所以DELETE请求也不需要request的body信息,就如上面的三个函数实现一样,非常简单。url指定DELETE请求的位置,urlVariables绑定url中的参数即可。
Ribbon小结
@LoadBalanced注解用来给RestTemplate做标记,以使用负载均衡的客户端(LoadBalancerClient)来配置它。
LoadBalancerAutoConfiguration为实现客户端负载均衡器的自动化配置类。
Ribbon实现的负载均衡自动化配置需要满足下面两个条件:
RestTemplate类必须存在于当前工程的环境中。- 在
Spring的Bean工程中必须有LoadBalancerClient的实现Bean。
自动化配置类中主要做了下面三件事:
- 创建了一个
LoadBalancerInterceptor的Bean,用于实现对客户端发起请求时进行拦截,以实现客户端负载均衡。 - 创建了一个
RestTemplateCustomizer的Bean,用于给RestTemplate增加LoadBalancerInterceptor拦截器。 - 维护了一个被
@LoadBalanced注解修饰的RestTemplate对象列表,并在这里进行初始化,通过调用RestTemplateCustomizer的实例来给需要客户端负载均衡的RestTemplate增加LoadBalancerInterceptor拦截器。
BaseLoadBalancer类实现了基础的负载均衡,而DynamicServerListLoadBalancer和ZoneAwareLoadBalancer在负载均衡的策略上做了一些功能的扩展。
在整合Ribbon的时候,Spring Cloud默认采用了ZoneAwareLoadBalancer来实现负载均衡器。
负载均衡器
AbstractLoadBalancer:ILoadBalancer接口的抽象实现。BaseLoadBalancer:Ribbon负载均衡器的基础实现类,在该类中定义了很多关于负载均衡器相关的基础内容。DynamicServerListLoadBalancer:继承于BaseLoadBalancer类,它是对基础负载均衡器的扩展。在该负载均衡器中,实现了服务实例清单在运行期的动态更新能力;同时,它还具备了对服务实例清单的过滤功能,也就是说,我们可以通过过滤器来选择性地获取一批服务实例清单。ZoneAwareLoadBalancer:是对DynamicServerListLoadBalancer的扩展。
自动化配置
在引入Spring Cloud Ribbon的依赖之后,就能够自动化构建下面这些接口的实现:
IClientConfig:Ribbon的客户端配置,默认采用com.netflix.client.config.DefaultClientConfigImpl实现。IRule:Ribbon的负载均衡策略,默认采用com.netflix.loadbalancer.ZoneAvoidanceRule实现,该策略能够在多区域环境下选出最佳区域的实例进行访问。IPing:Ribbon的实例检查策略,默认采用com.netflix.loadbalancer.NoOpPing实现,该检查策略是一个特殊的实现,实际上它并不会检查实例是否可用,而是始终返回true,默认认为所有服务实例都是可用的。ServerList<Server>:服务实例清单的维护机制,默认采用com.netflix.loadbalancer.ConfigurationBasedServerList实现。ServerListFilter<Server>:服务实例清单过滤机制,默认采用org.springframework.cloud.netflix.ribbon.ZonePrefenceServerListFilter实现,该策略能够优先过滤出与请求调用方处于同区域的服务实例。ILoadBalancer:负载均衡器,默认采用com.netflix.loadbalancer.ZoneAwareLoadBalancer实现,它具备了区域感知的能力。
上面这些自动化配置内容仅在没有引入Spring Cloud Eureka等服务治理框架时如此,在同时引入Eureka和Ribbon依赖时,自动化配置会有一些不同。
通过自动化配置的实现,可以轻松地实现客户端负载均衡。同时,针对一些个性化需求,也可以方便地替换上面的这些默认实现。只需要在Spring Boot应用中创建对应的实现实例就能覆盖这些默认的配置实现。比如下面的配置内容,由于创建了PingUrl实例,所以默认的NoOpPing就不会被创建。
@Configurationpublic class MyRibbonCconfiguration{ @Bean public IPing ribbonPing(IClientConfig config){ return new PingUrl(); }} 另外,也可以通过使用@RibbonClient注解来实现更细粒度的客户端配置,比如下面的代码实现了为hello-service服务使用HelloServiceConfiguration中的配置。
@Configuration@RibbonClient(name="hello-service",configuration=HelloServiceConfiguration.class)public class RibbonConfiguration{ } Camden版本对RibbonClient配置的优化
上面介绍在Brixton版本中对RibbonClient的IPing、IRule等接口实现进行个性化定制的方法,主要通过独立创建一个Configuration类来定义IPing、IRule等接口的具体实现Bean,然后在创建RibbonClient时制定要使用的具体Configuration类来覆盖自动化配置的默认实现。虽然这种方式已经能够实现个性化的定义,但是当有大量这类配置的时候,对于各个RibbonClient的制定配置信息都将分散在这些配置类的注解定义中,这使得管理和修改都变得非常不方便。所以,在Camden版本中,Sping Cloud Ribbon对RibbonClient定义个性化配置的方法做了进一步优化。可以直接通过<clientName>.ribbon.<key>=<value>的形式进行配置。比如我们要实现与上面例子一样的配置(将hello-service服务客户端的IPing接口实现替换为PingUrl),只需在application.properties配置中增加如下内容即可:
hello-service.ribbon.NFLoadBalancePingClassName=com.netflix.loadbalancer.PingUrl
其中hello-service为服务名,NFLoadBalancerPingClassName参数用来指定具体的IPing接口实现类。
在Camden版本中我们可以通过配置的方式,更加方便地为RibbonClient指定ILoadBalancer、IPing、IRule、ServerList和ServerListFilter的定制化实现。
参数配置
对于Ribbon的参数配置通常有两种方式:全局配置以及指定客户端配置。
- 全局配置方式很简单,只需使用
ribbon.<key>=<value>格式进行配置即可。 其中,<key>代表了Ribbon客户端配置的参数名,<value>则代表了对应参数的值。全局配置可以作为默认值进行设置,当指定客户端配置了相应key的值时,将覆盖全局配置的内容。我们可以像下面这样全局配置Ribbon创建连接的超时时间:
ribbon.ConnetcTimeout=250
- 指定客户端的配置方式采用
<client>.ribbon.<key>=<value>的格式进行配置。其中,<key>和<value>的含义同全局配置相同,而<client>代表了客户端的名称,如上文中我们在@RibbonClient中指定的名称,也可以将它理解为是一个服务名。为了方便理解这种配置方式,举一个例子:假设,有一个服务消费者通过RestTemplate来访问hello-service服务的/hello接口,这时会这样调用restTemplate.getForEntity(“http://hello-service/hello“,String.class).getBody();如果没有服务治理框架的帮助,我们需要为该客户端指定具体的实例清单,可以指定服务名来做详细的配置,具体如下:
hello-service.ribbon.listOfServers=localhost:8001,localhost:8002,localhost:8003
与Eureka结合
当在Spring Cloud的应用中同时引入Spring Cloud Ribbon和Spring Cloud Eureka依赖时,会触发Eureka中实现的对Ribbon的自动化配置。这时ServerList的维护机制实现将被com.netflix.niws.loadbalancer.DiscoveryEnabledNIWSServerList的实例所覆盖,该实现会将服务清单列表交给Eureka的服务治理机制来进行维护;IPing的实现将被com.netflix.niws.loadbalancer.NIWSDiscoveryPing的实例所覆盖,该实现也将实例检查的任务交给了服务治理框架来进行维护。默认情况下,用于获取实例请求的ServerList接口实现将采用Spring Cloud Eureka中封装的org.springframework.cloud.netflix.ribbon.eureka.DomainExtractingServerList,其目的是为了让实例维护策略更加通用,所以将使用物理元数据来进行负载均衡,而不是使用原生的AWS AMI元数据。
由于Spring Cloud Ribbon默认实现了区域亲和策略,所以,可以通过Eureka实例的元数据配置来实现区域化的实例配置方案。比如,可以将处于不同机房的实例配置成不同的区域值,以作为跨区域的容错机制实现。而实现的方式非常简单,只需要在服务实例的元数据中增加zone参数来指定自己所在的区域,比如:
eureka.instance.metadataMap.zone=shanghai
在Spring Cloud Ribbon与Spring Cloud Eureka结合的工程中,我们也可以通过参数配置的方式来禁用Eureka对Ribbon服务实例的维护实现。只需要在配置中加入如下参数,这时我们对于服务实例的维护就又回归到使用<client>.ribbon.listOfServers参数配置的方式来实现了。
ribbon.eureka.enabled=false
重试机制
由于Spring Cloud Eureka实现的服务治理机制强调了CAP原理中的AP,即可用性与可靠性,它与ZooKeeper这类强调CP(一致性、可靠性)的服务治理框架最大的区别就是,Eureka为了实现更高的服务可用性,牺牲了一定的一致性,在极端情况下它宁愿接受故障实例也不要丢掉“健康”实例,比如,当服务注册中心的网络发生故障断开时,由于所有的服务实例无法维持续约心跳,在强调AP的服务治理中会把所有服务实例都剔除掉,而Eureka则会因为超过85%的实例丢失心跳而会触发保护机制,注册中心将会保留此时的所有节点,以实现服务间依然可以进行互相调用的场景,即使其中有部分故障节点,但这样做可以继续保障大多数的服务正常消费。
由于Spring Cloud Eureka在可用性与一致性上的取舍,不论是由于触发了保护机制还是服务剔除的延迟,引起服务调用到故障实例的时候,我们还是希望能够增强对这类问题的容错。所以,我们在实现服务调用的时候通常会加入一些重试机制。从Camden SR2版本开始,Spring Cloud整合了Spring Retry来增强RestTemplate的重试能力,对于开发者来说只需通过简单的配置,原来那些通过RestTemplate实现的服务访问就会自动根据配置来实现重试策略。
以之前对hello-service服务的调用为例,可以在配置文件中增加如下内容:
spring.cloud.loadbalancer.retry.enabled=truehystrix.command.default.execution.isolation.thread.timeoutInMillseconds=10000hello-service.ribbon.ConnetTimeout=250hello-service.ribbon.ReadTimeout=1000hello-service.ribbion.OkToRetryOnAllOperations=truehello-service.ribbon.MaxAutoRetriesNextServer=2hello-service.ribbon.MaxAutoRetries=1
说明:
spring.cloud.loadbalancer.retry.enabled:该参数用来开启重试机制,它默认是关闭的。hystrix.command.default.execution.isolation.thread.timeoutInMillseconds:断路器的超时时间需要大于Ribbon的超时时间,不然不会触发重试。hello-service.ribbon.ConnectTimeout:请求连接的超时时间。hello-service.ribbon.ReadTimeout:请求处理的超时时间。hello-service.ribbon.OkToRetryOnAllOperations:对所有操作请求都进行重试。hello-service.ribbon.MaxAutoRetriesNextServer:切换实例的重试次数。hello-service.ribbon.MaxAutoRetries:对当前实例的重试次数。
根据如上配置,当访问到故障请求的时候,它会再尝试访问一次当前实例(次数由MaxAutoRetries配置),如果不行,就换一个实例进行访问,如果还不行,再换一次实例访问(更换次数由MaxAutoRetriesNextServer配置),如果依然不行,返回失败信息。
Feign
Spring Cloud Ribbon和Spring Cloud Hystrix被作为基础工具类框架广泛地应用在各个微服务的实现中,不仅包括我们自身的业务类微服务,也包括一些基础设施类微服务(比如网关)。此外,在实践过程中,我们会发现对这两个框架的使用几乎是同时出现的。Spring Cloud Feign就是整合了这两个基础工具来简化开发的一个工具。
Spring Cloud Feign是一套基于Netflix Feign实现的声明式服务调用客户端。它整合了Spring Cloud Ribbon与Spring Cloud Hystrix,除了提供这两者的强大功能之外,它还提供了一种声明式的Web服务客户端定义方式。
它使得编写Web服务客户端变得更加简单。我们只需要通过创建接口并用注解来配置它,即可完成对服务提供方的接口绑定,简化了在使用Spring Cloud Ribbon时自行封装服务调用客户端的开发量。
它具备可插拔的注解支持,包括Feign注解、JAX-RS注解。它也支持可插拔的编码器和解码器。Spring Cloud Feign还扩展了对Spring MVC注解的支持,同时还整合了Ribbon和Eureka来提供均衡负载的HTTP客户端实现。
前面在使用Ribbon+RestTemplate时,利用RestTemplate对http请求的封装处理,形成了一套模板化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行封装一些客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进一步封装,由他来帮助我们定义和实现依赖服务接口的定义。在Feign的实现下,我们只需创建一个接口并使用注解的方式来配置它(以前是Dao接口上面标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解即可),即可完成对服务提供方的接口绑定,简化了使用Spring Cloud Ribbon时,自动封装服务调用客户端的开发量。
集成Feign
开发环境
JDK8+Gradle4+Redis 3.2.100Spring Boot 2.0.0.M3Spring Cloud Starter Netflix Eureka Client Finchley.M2Spring Cloud Starter OpenFeign Finchley.M2
创建项目
复制之前的micro-weather-eureka-client项目,将副本改名为micro-weather-eureka-client-feign
修改源码
修改build.gradle配置,添加Feign依赖:
//依赖关系dependencies { //Eureka Client compile('org.springframework.cloud:spring-cloud-starter-netflix-eureka-client') //Feign compile('org.springframework.cloud:spring-cloud-starter-openfeign:2.0.0.M3') //该依赖用于测试阶段 testCompile('org.springframework.boot:spring-boot-starter-test')} 此处要注意Feign依赖的版本,如果不加版本号,将默认下载2.0.0.M2版本,源码中是没有LoadBalancedRetryFactory的,运行会导致以下报错:
java.lang.ClassNotFoundException: org.springframework.cloud.client.loadbalancer.LoadBalancedRetryFactory
修改com.study.spring.cloud.weather包下的Application类,加入@EnableFeignClients注解,开启扫描Spring Cloud Feign客户端的功能:
package com.study.spring.cloud.weather;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.cloud.client.discovery.EnableDiscoveryClient;import org.springframework.cloud.netflix.feign.EnableFeignClients;/* * @SpringBootApplication注解声明Spring Boot应用 * 作用等同于@Configuration, @EnableAutoConfiguration, @ComponentScan, * 简化Spring配置*/@SpringBootApplication//启用可发现的客户端@EnableDiscoveryClient//启用Feign@EnableFeignClients//Application类一定要处于整个工程的根目录下,这样它才能根据配置去扫描子节点下的Spring的Beanpublic class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); }} 新建com.study.spring.cloud.weather.service包,在包下新建接口CityClient,使用@FeignClient注解来指定这个接口所要调用的服务名称,接口中定义的各个函数使用Spring MVC的注解就可以来绑定服务提供方的REST接口:
package com.study.spring.cloud.weather.service;import org.springframework.cloud.netflix.feign.FeignClient;import org.springframework.web.bind.annotation.GetMapping;//指明服务地址@FeignClient("mas-weather-city-eureka")public interface CityClient { @GetMapping("/cities") String listCity();} 这里服务名不区分大小写,所以使用mas-weather-city-eureka和MAS-WEATHER-CITY-EUREKA都是可以的。
在com.study.spring.cloud.weather.controller包下新建类CityController,使用@Autowired直接注入上面定义的CityClient实例,并在listCity函数中调用这个绑定了mas-weather-city-eureka服务接口的客户端来向该服务发起/cities接口的调用,通过定义的Feign客户端来调用服务提供方的接口:
package com.study.spring.cloud.weather.controller;import com.study.spring.cloud.weather.service.CityClient;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RestController;//用于处理rest请求的controller@RestControllerpublic class CityController { @Autowired private CityClient cityClient; @GetMapping("/cities") public String listCity() { //通过Feign客户端来查找 String body=cityClient.listCity(); return body; } } 修改application.properties配置文件:
#应用名称spring.application.name=micro-weather-eureka-client-feign#注册服务器的URLeureka.client.service-url.defaultZone=http://localhost:8761/eureka/#请求服务时的超时时间feign.client.config.feignName.connect-timeout=5000#读数据时的超时时间feign.client.config.feignName.read-timeout=5000
运行
- 先在
IDE上运行micro-weather-eureka-server - 再通过命令行运行
msa-weather-city-eureka: 因为之前已经编译过,直接进入E:\workspace\workspace-study\springcloud-study\imooc-spring-cloud-study\msa-weather-city-eureka\build\libs目录, 再通过命令java -jar msa-weather-city-eureka-1.0.0.jar --server.port=8081运行jar包即可 - 在
IDE上运行micro-weather-eureka-client-feign,运行结果如下: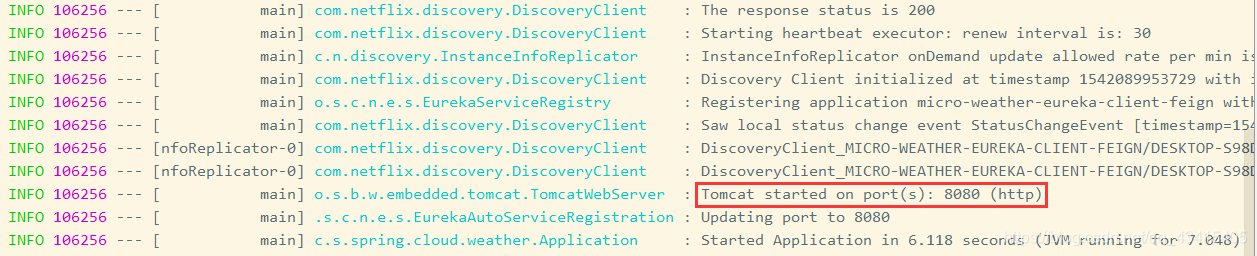
- 访问
http://localhost:8761页面,可以看到Eureka的管理页面: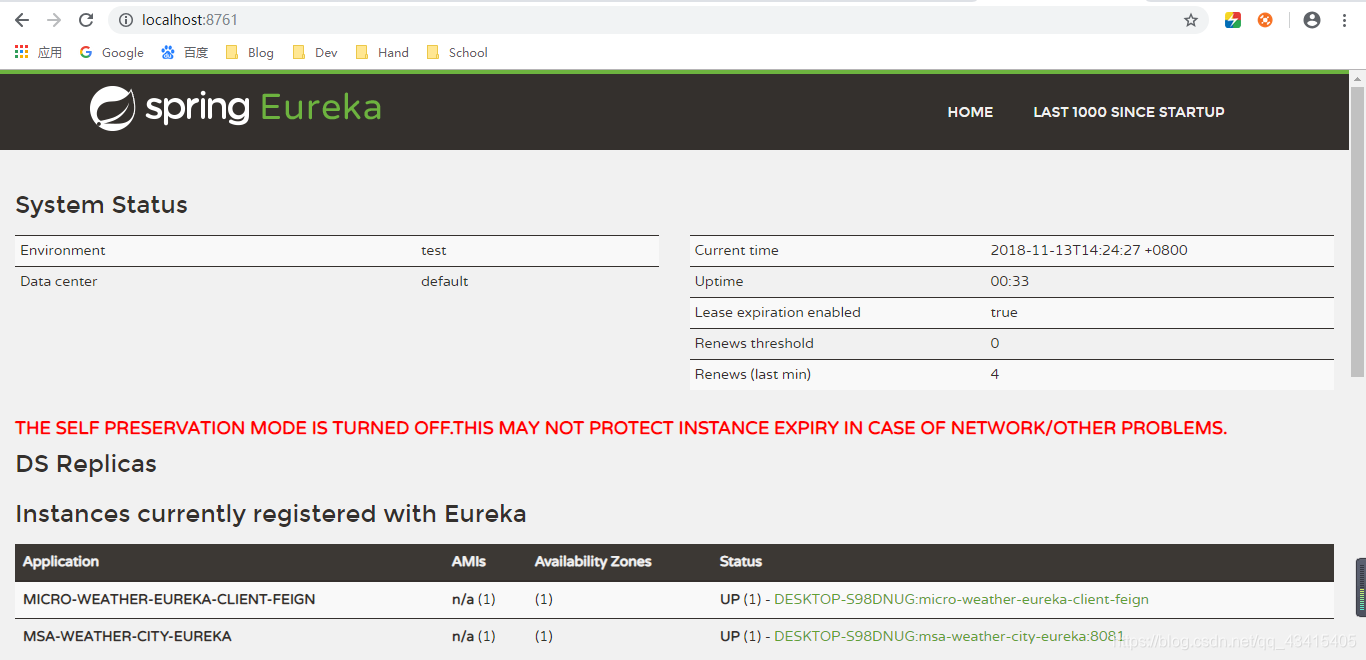
- 访问
http://localhost:8080/cities页面: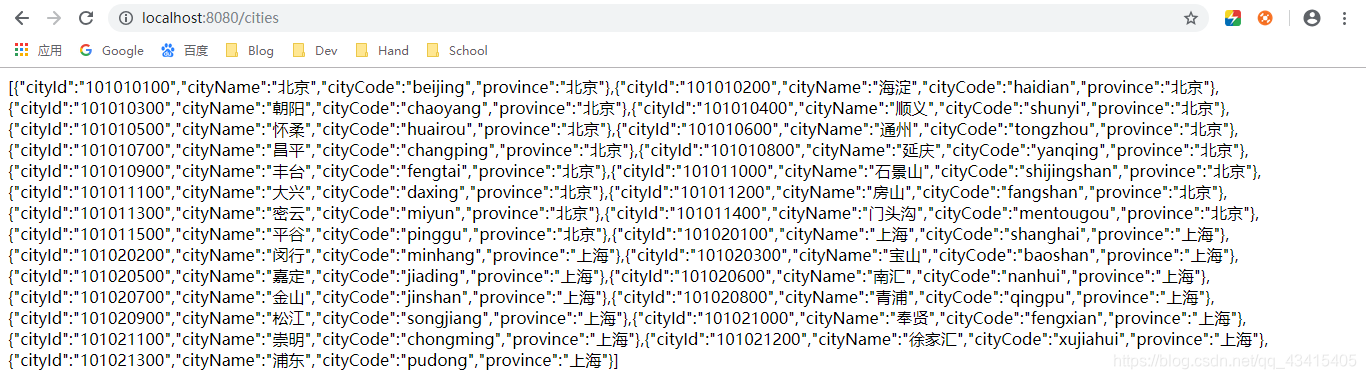
通过Spring Cloud Feign来实现服务调用的方式更加简单了,通过@FeignClient定义的接口来统一的生命我们需要依赖的微服务接口。而在具体使用的时候就跟调用本地方法一点的进行调用即可。由于Feign是基于Ribbon实现的,所以它自带了客户端负载均衡功能,也可以通过Ribbon的IRule进行策略扩展。另外,Feign还整合的Hystrix来实现服务的容错保护,在Dalston版本中,Feign的Hystrix默认是关闭的。
Hystrix配置
在Spring Cloud Feign中,除了引入了用于客户端负载均衡的Spring Cloud Ribbon之外,还引入了服务保护与容错的工具Hystrix。默认情况下,Spring Cloud Feign会为将所有Feign客户端的方法都封装到Hystrix命令中进行服务保护。
全局配置
对于Hystrix的全局配置同Spring Cloud Ribbon的全局配置一样,直接使用它的默认配置前缀hystrix.command.default就可以进行设置,比如设置全局的超时时间:
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=5000
另外,在对Hystrix进行配置之前,我们需要确认feign.hystrix.enabled参数没有被设置为false,否则该参数设置会关闭Feign客户端的Hystrix支持。
指定命令配置
对于Hystrix命令的配置,在实际应用时往往也会根据实际业务情况制定出不同的配置方案。配置方法也跟传统的Hystrix命令的参数配置相似,采用hystrix.command.<commandKey>作为前缀。而<commandKey>默认情况下会采用Feign客户端中的方法名作为标识,比如对/hello接口的熔断超时时间的配置可以通过其方法名作为<commandKey>来进行配置,具体如下:
hystrix.command.hello.execution.isolation.thread.timeoutInMilliseconds=5000
在使用指定命令配置的时候,需要注意,由于方法名很有可能重复,这个时候相同方法名的Hystrix配置会共用,所以在进行方法定义与配置的时候需要做好一定的规划。当然,也可以重写Feign.Builder的实现,并在应用主类中创建它的实例来覆盖自动化配置的HystrixFeign.Builder实现。
其他配置
请求压缩
Spring Cloud Feign支持对请求与响应进行GZIP压缩,以减少通信过程中的性能损耗。我们只需通过下面两个参数设置,就能开启请求与响应的压缩功能:
feign.compression.request.enabled=truefeign.compression.response.enabled=true
同时,我们还能对请求压缩做一些更细致的设置,比如下面的配置内容指定了压缩的请求数据类型,并设置了请求压缩的大小下限,只有超过这个大小的请求才会对其进行压缩。
feign.compression.request.enabled=truefeign.compression.request.mime-types=text/xml,application/jsonfeign.compression.request.min-request-size=2048
上述配置的feign.compression.request.mime-types和feign.compression.request.min-request-size均为默认值。
转载地址:http://hgiwi.baihongyu.com/